As promised, here are the slides and notes from my DSDC talklet on strategies for incorporating text data into the feature set of a predictive model. Slides Notes github Thanks to Harlan for asking, and to Dan and David for...

Redos of the plots from this post: Bit more communicative, though the overplotting is a bit annoying. Code: ## gis libraries library(spBayes) library(MBA) library(geoR) library(fields) library(sp) library(maptools) library(rgdal) library(classInt) library(lattice) library(xtable) library(spatstat) library(splancs) ## Other packages library(ggplot2) library(foreign) library(stringr) library(lubridate)...

A few quick plots of West Baltimore neighborhoods, first Sandtown-Winchester: and Harlem Park: These aren't very polished, I'll put up better versions. Here's the code for those that want it: ## gis libraries library(spBayes) library(MBA) library(geoR) library(fields) library(sp) library(maptools) library(rgdal)...
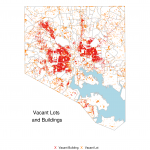
One of the key predictors in my model for this crime project I'm working on is vacant houses and lots. I'll speak to some findings about the relationship between levels of the different types of crime and vacant property in...
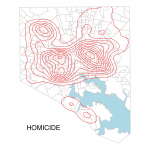
The advent of municipal open data initiatives has been both a blessing and curse for my particular brand of data nerd. On one hand, it has opened up the possibility of developing deep and useful knowledge about the places we...
Thanks to everyone for coming out. Slides can be found here. Doesn't work well in mobile and touchscreen browsers. Code for simulation can be found here. Code for polling data example can be found here. I learned a lot from...
Because I am self-taught in many of the areas of computer science and more advanced statistics and probability theory I am most interested in, and because I have a deep aversion both to looking foolish and being full of it...
Think of something observable - countable - that you care about with only one outcome or another. It could be the votes cast in a two-way election in your town, or the free throw shots the center on your favorite...
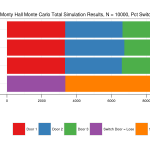
While I dig into conjugacy and the calculation of Bayesian credibility intervals, I figured it'd be good to put some of my other little rabbit holes up here on the off chance they're interesting to someone. For some reason I...
Most of the applications of Bayesian methods I've encountered and used to date are in the areas of text mining and machine learning, such as topic modeling using LDA models, naive bayes classifiers, and in time series analysis (Kalman filters...
